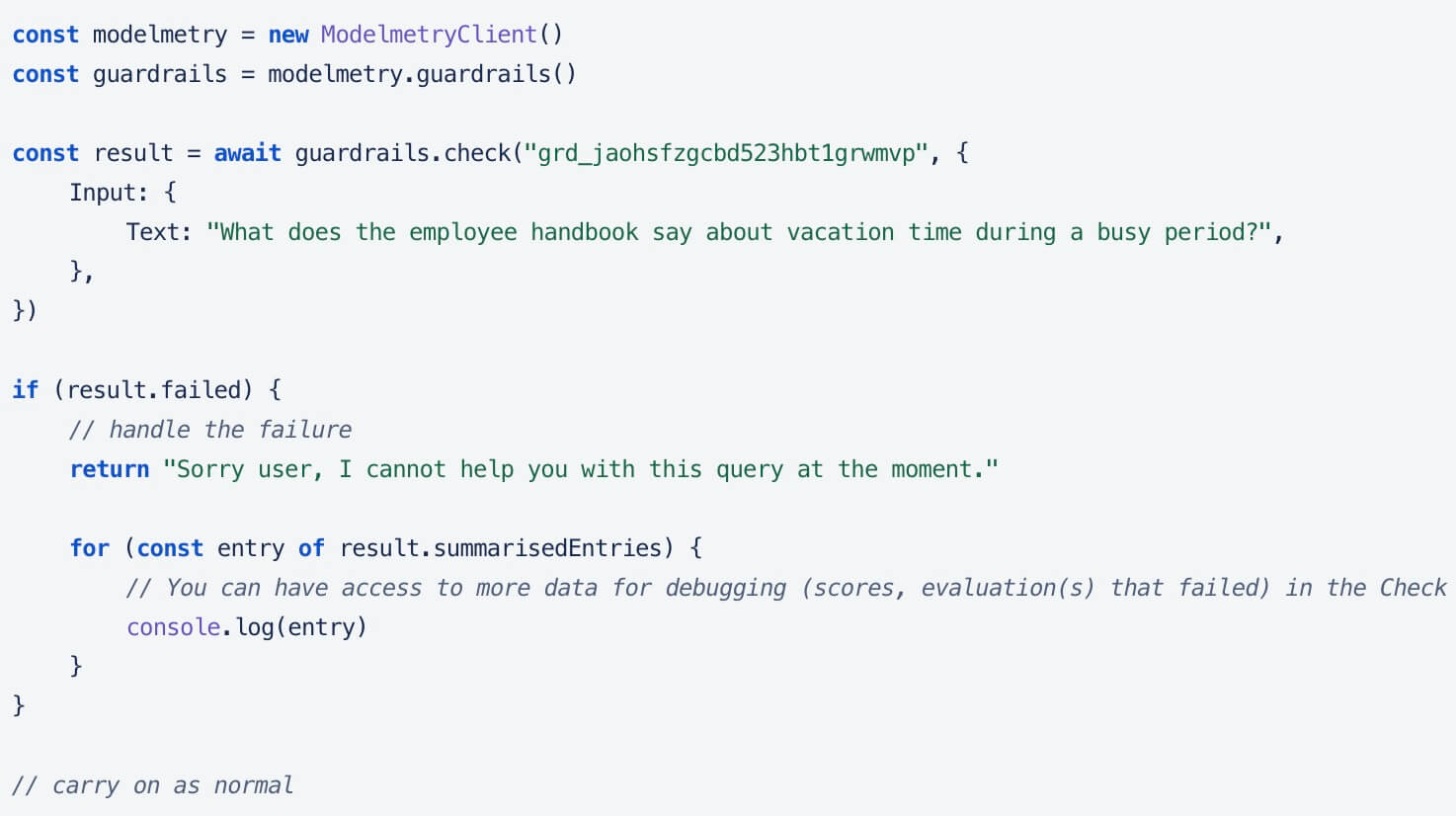
Jailbreak & Prompt Injection
Prevent your LLM from getting jailbroken using prompt injection and other latest threat vectors.
Protect against jailbreaks, hallucinations, and malicious inputs, while ensuring correct LLM behavior with detailed traces, spans, and metrics.
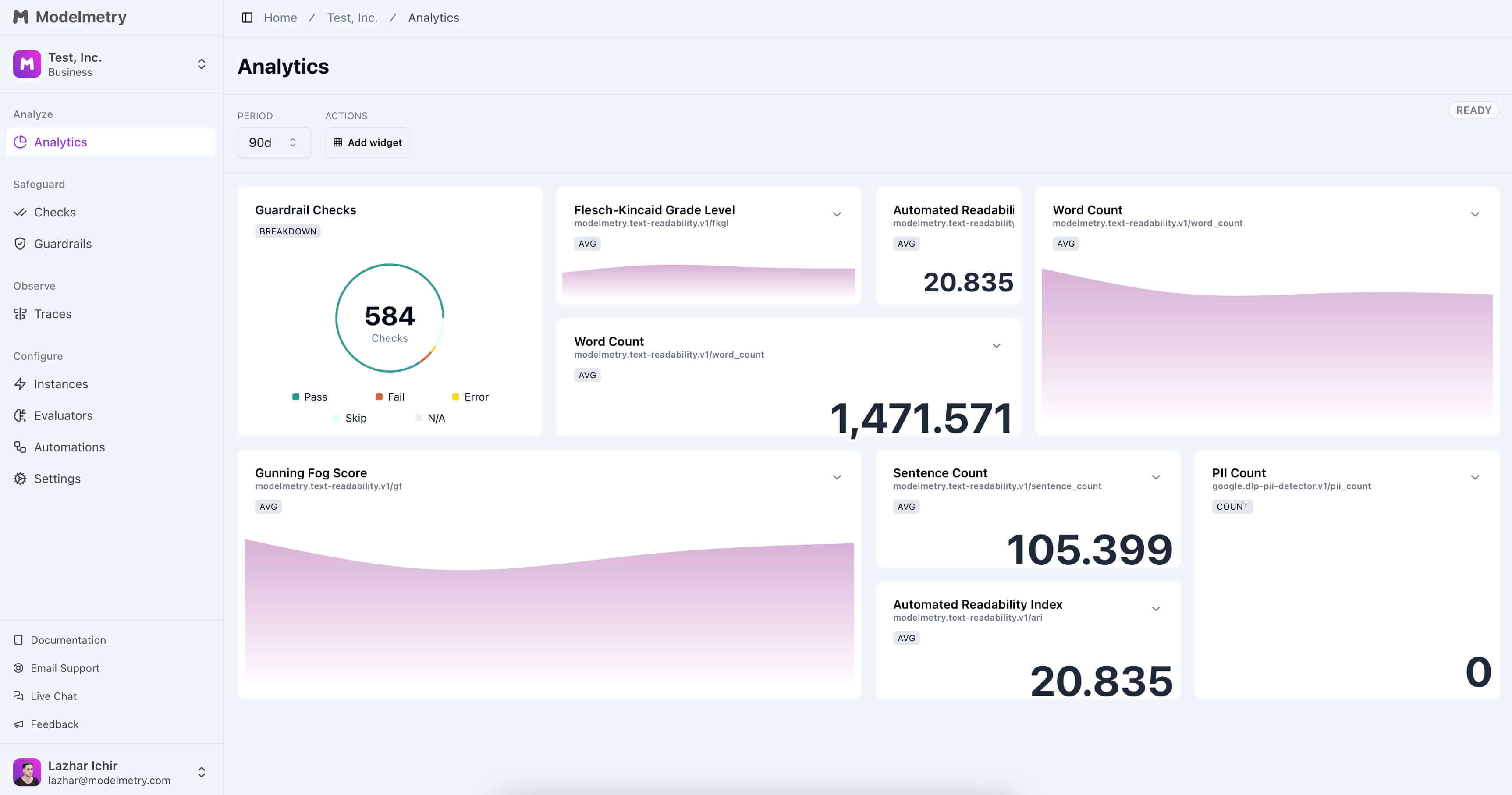
Check user inputs and LLM outputs with our built-in evaluators, or create your custom guardrails. We support text, conversations, RAG, and even tools.
Prevent your LLM from getting jailbroken using prompt injection and other latest threat vectors.
Check if the LLM output is grounded in RAG contextual documents, and not hallucinating.
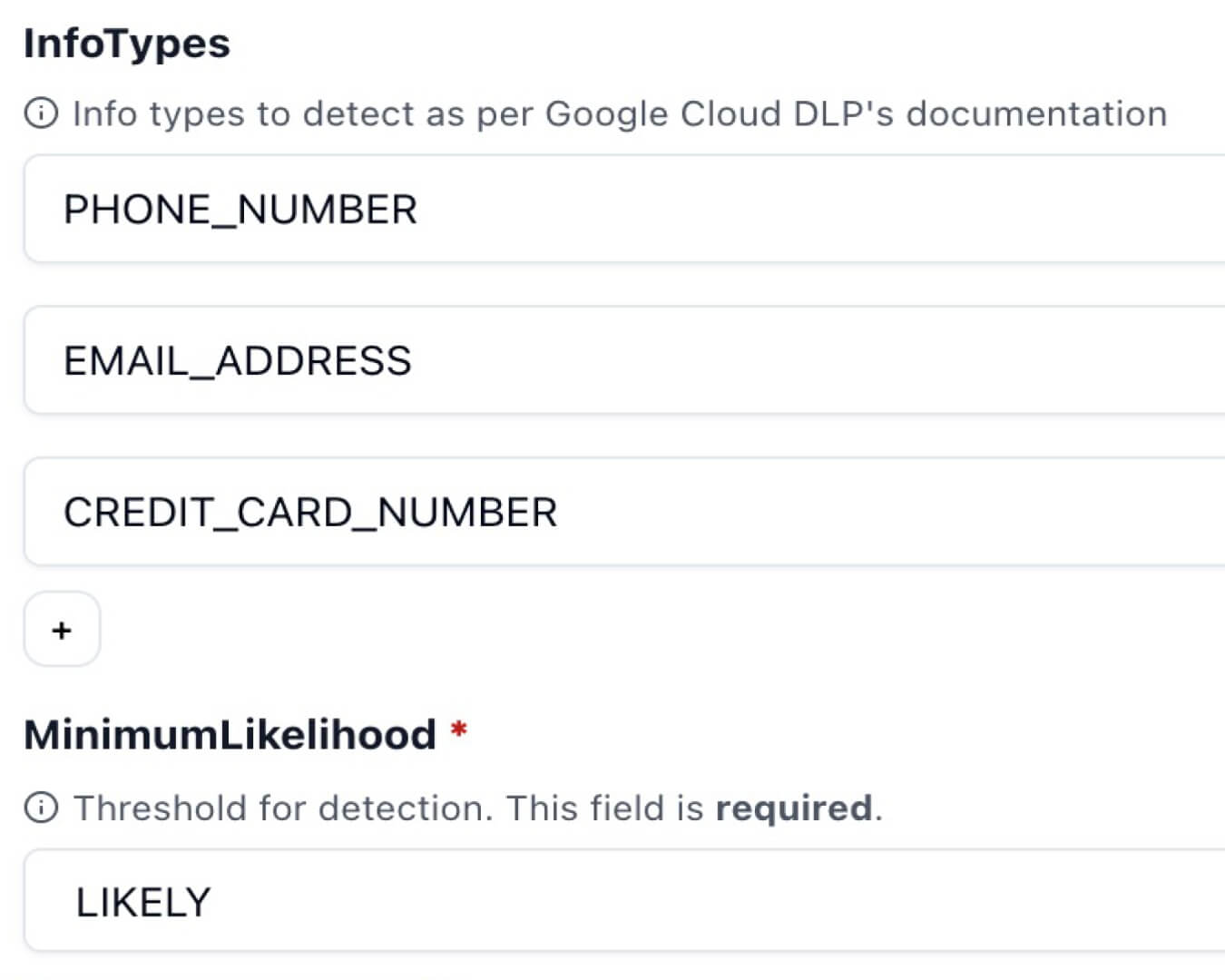
Detect political, legal, medical, or even religious content from being discussed.
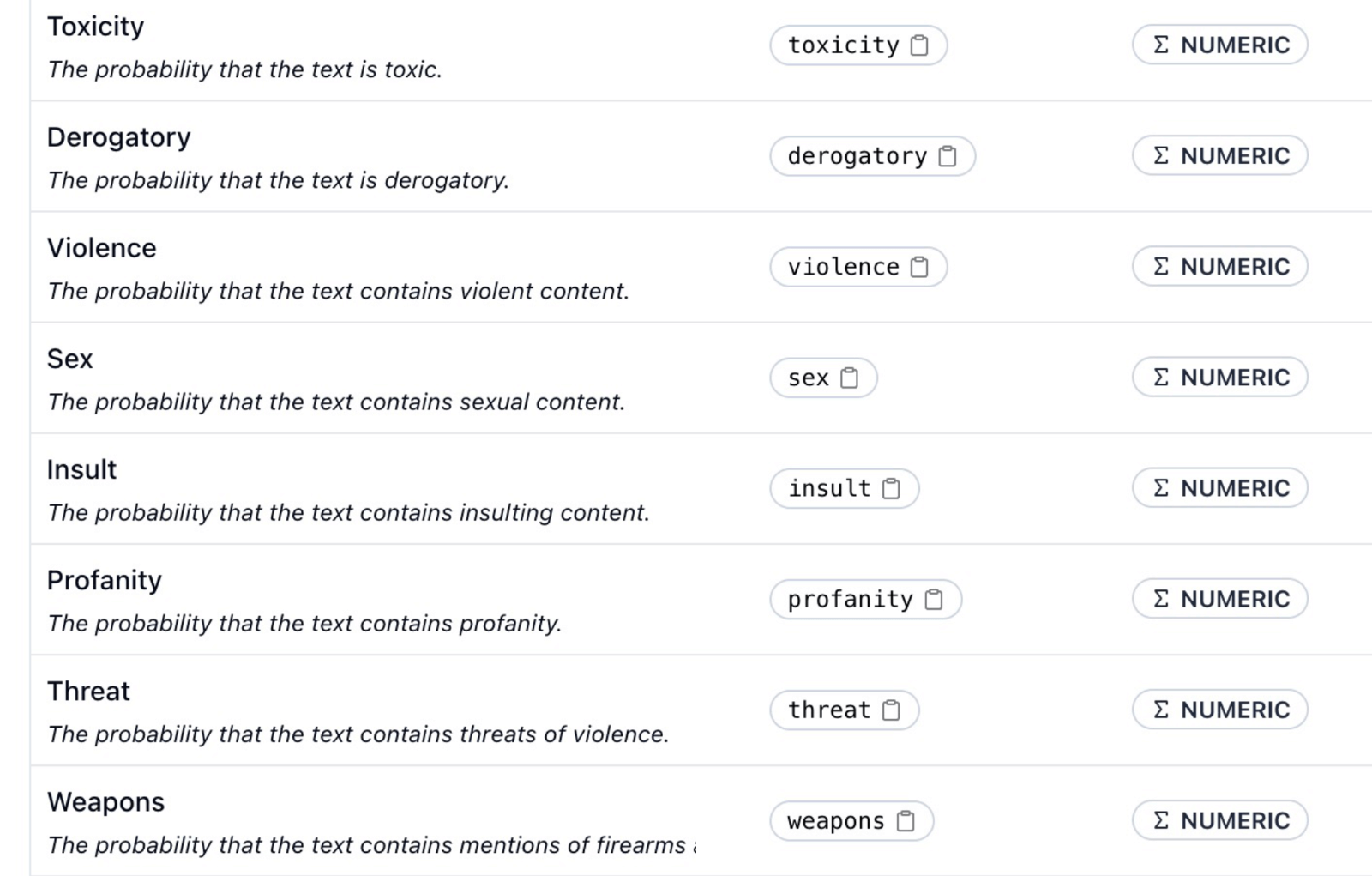
Filter out offensive and threatening language as well as hate speech from your LLM.
Catch personally identifiable information from your LLM outputs, especially when using RAG.
Ensure LLM output is valid JSON, and conforms to a specific JSON Schema.
Detect the leaking of private keys, tokens, and other secrets within your outputs.
Block competitors from being mentioned in your LLM outputs and avoid embarrassment.
Identify and grade the tone and mood of your LLM outputs to ensure they are appropriate.
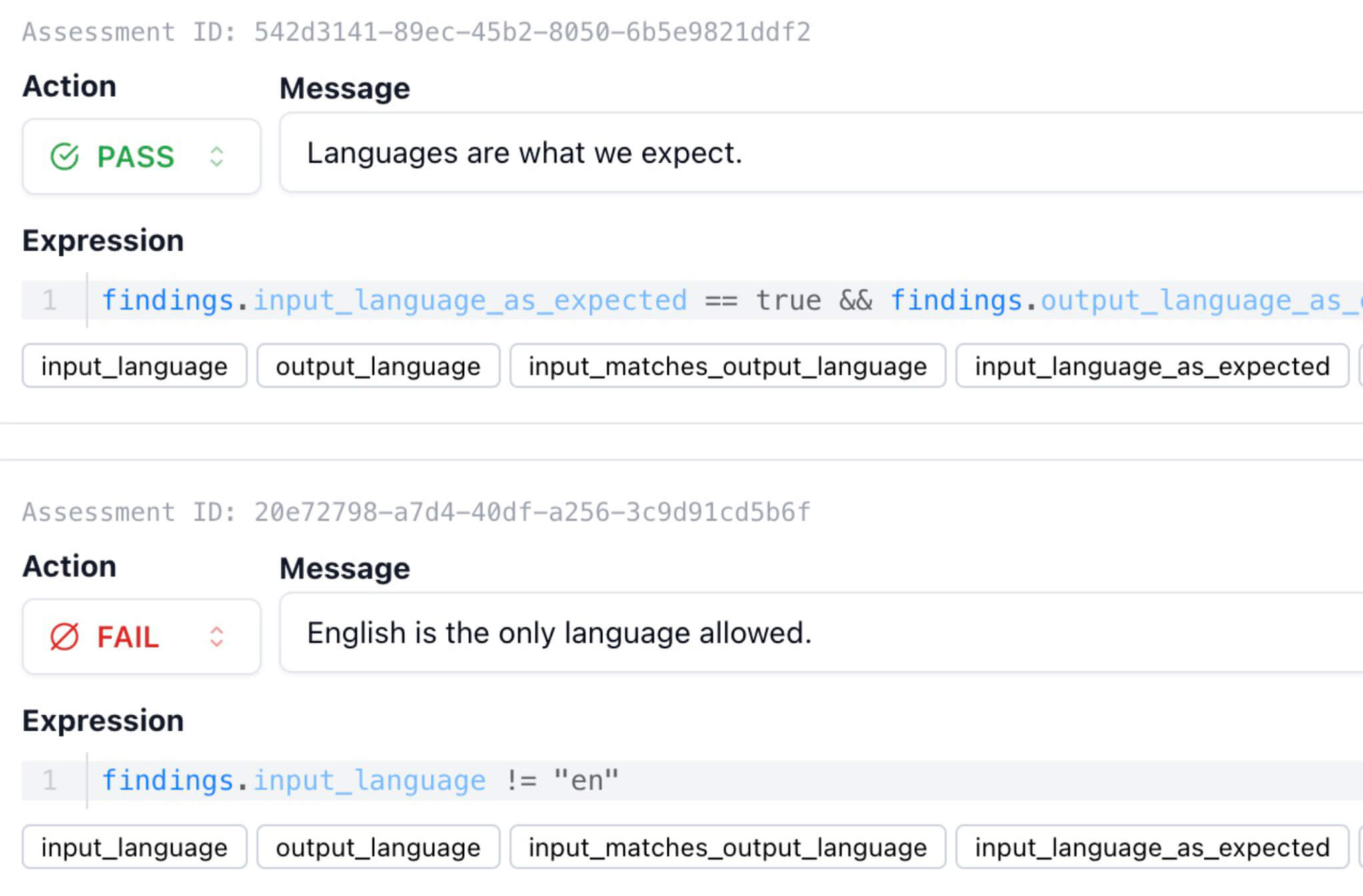
Ensure the LLM output matches the user input to avoid language confusion.
Compare input and output embeddings to ensure the LLM is on topic and relevant.
Detect the emotions in the content and ensure they are appropriate.
Determines if a payload has a positive, negative, or neutral sentiment.
Compares how similar two embeddings are (e.g., user input vs LLM output, or vs a reference text).






typescriptModelmetry is designed, from the ground up, to be a powerful yet simple-to-use platform for managing and monitoring your LLM applications.
Enforce safety and quality guidelines for your LLM application with real-time checks on user inputs and model outputs.

Create dead-simple or highly customizable pass/fail rules for evaluations with an expressive grading system which offers granular control.
Track key performance indicators (KPIs) like latency, cost, and token usage for optimized performance and cost management.
Use instrumentation, traces, spans, and events to monitor and gain deep insights into your LLM application's behavior.
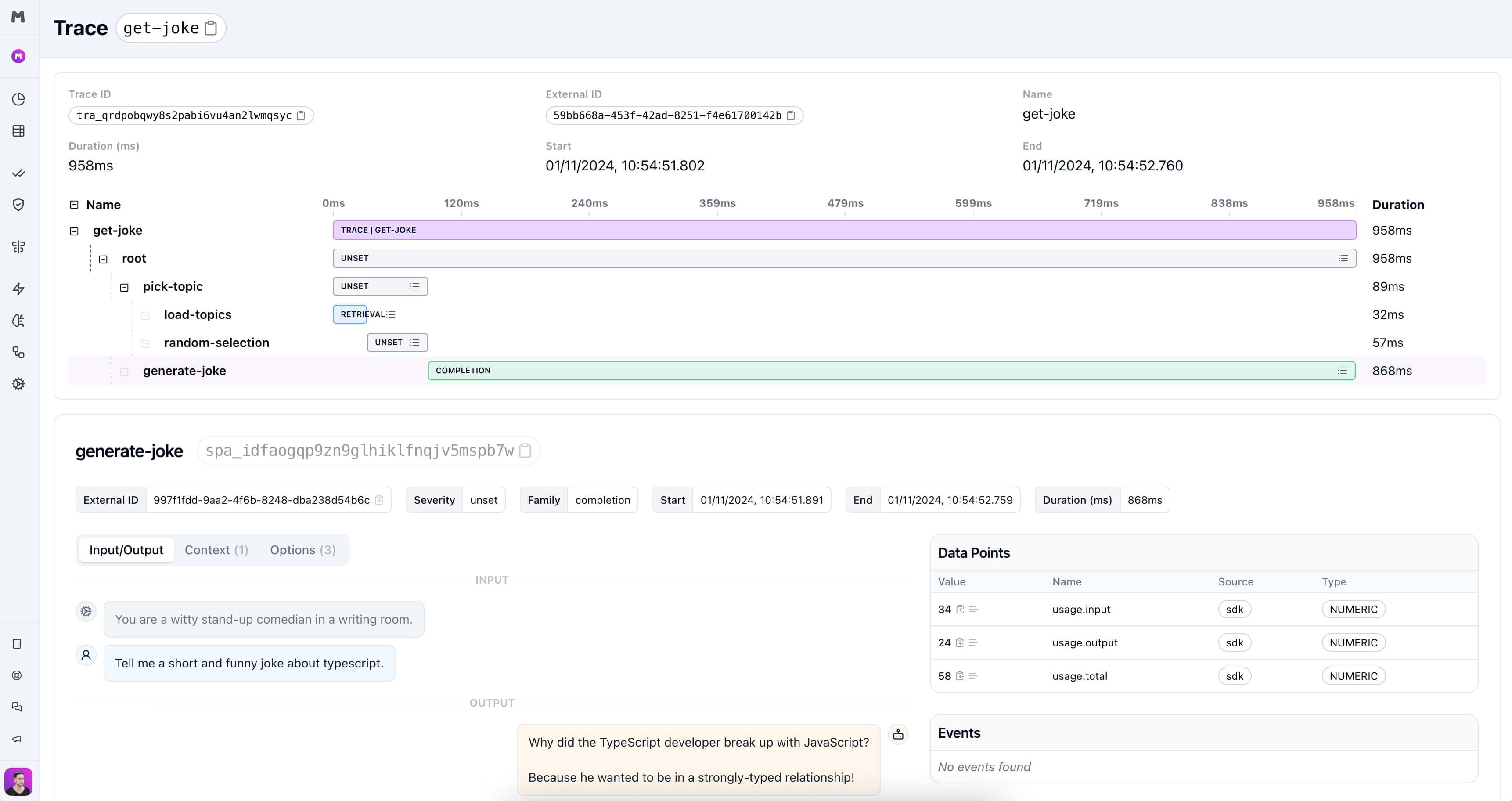
Leverage advanced, pre-built evaluators for detecting threats, jailbreaks, toxicity, and other qualitative metrics.

Tailor Modelmetry to your specific needs with configurable evaluations, metrics, and automations. Or use sane defaults.
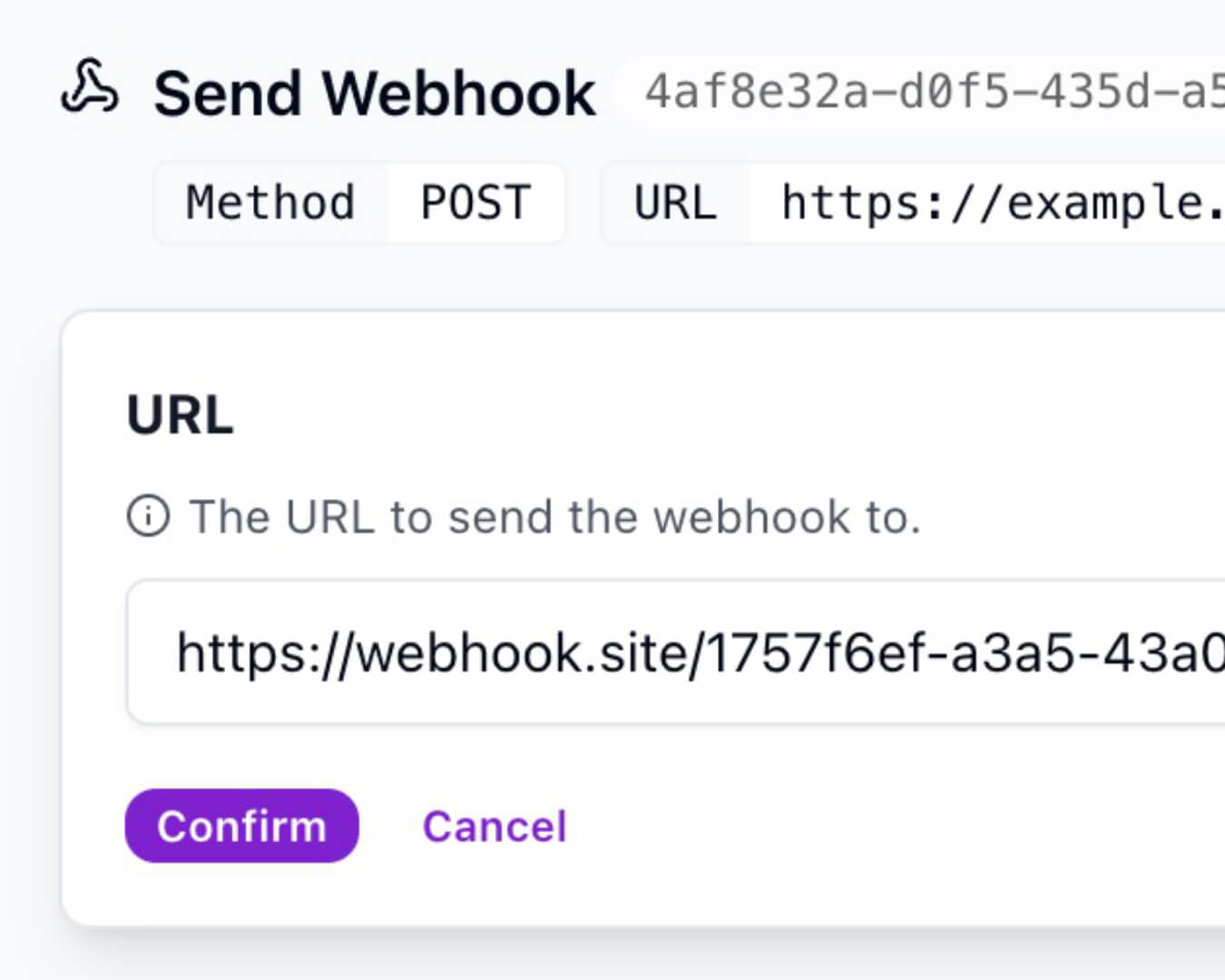
Integrate seamlessly with your existing tools and services through flexible webhook integrations.
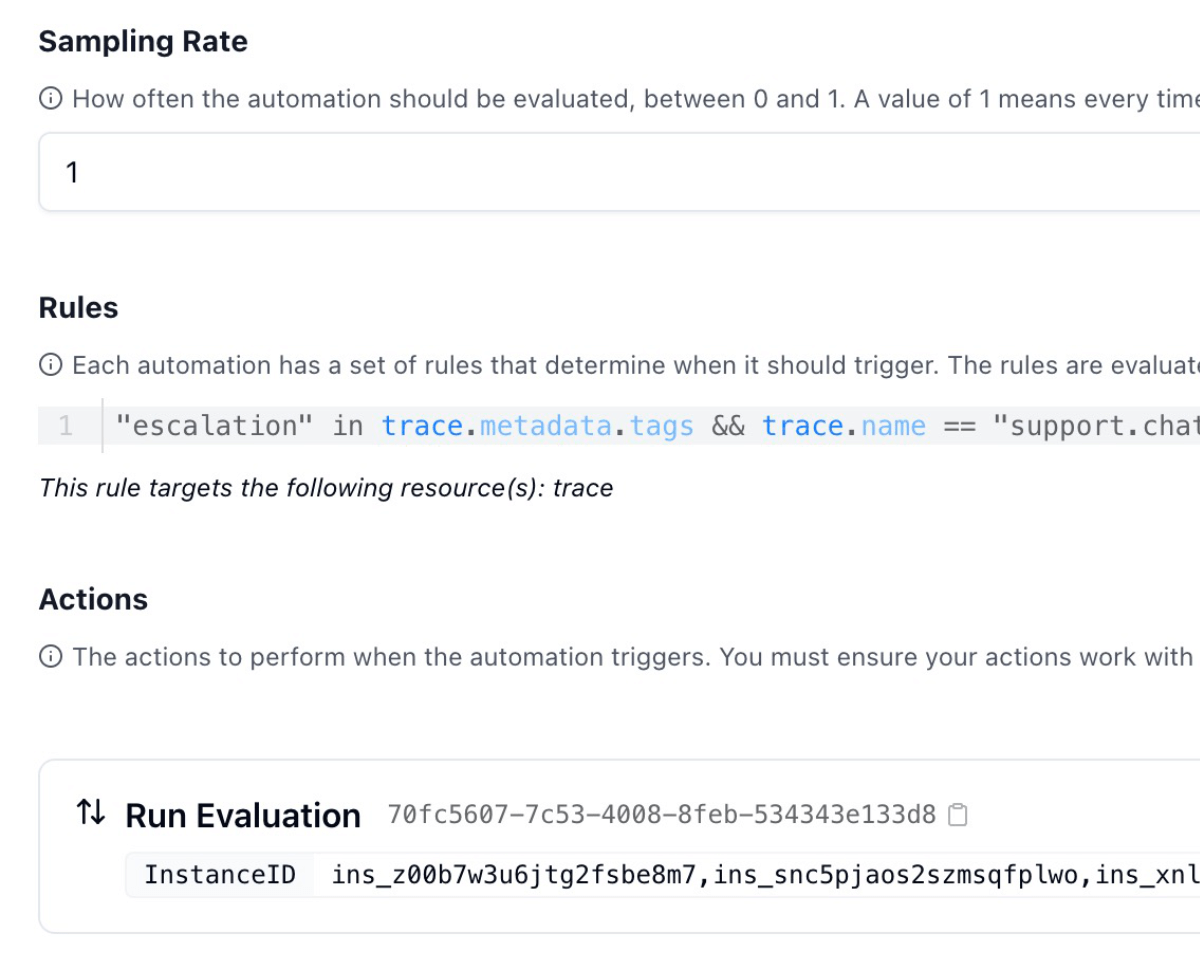
Streamline workflows and enforce policies by triggering actions based on real-time data from your LLM application.
Easily instrument your LLM application with our lightweight, open-source SDKs for Python and Typescript.
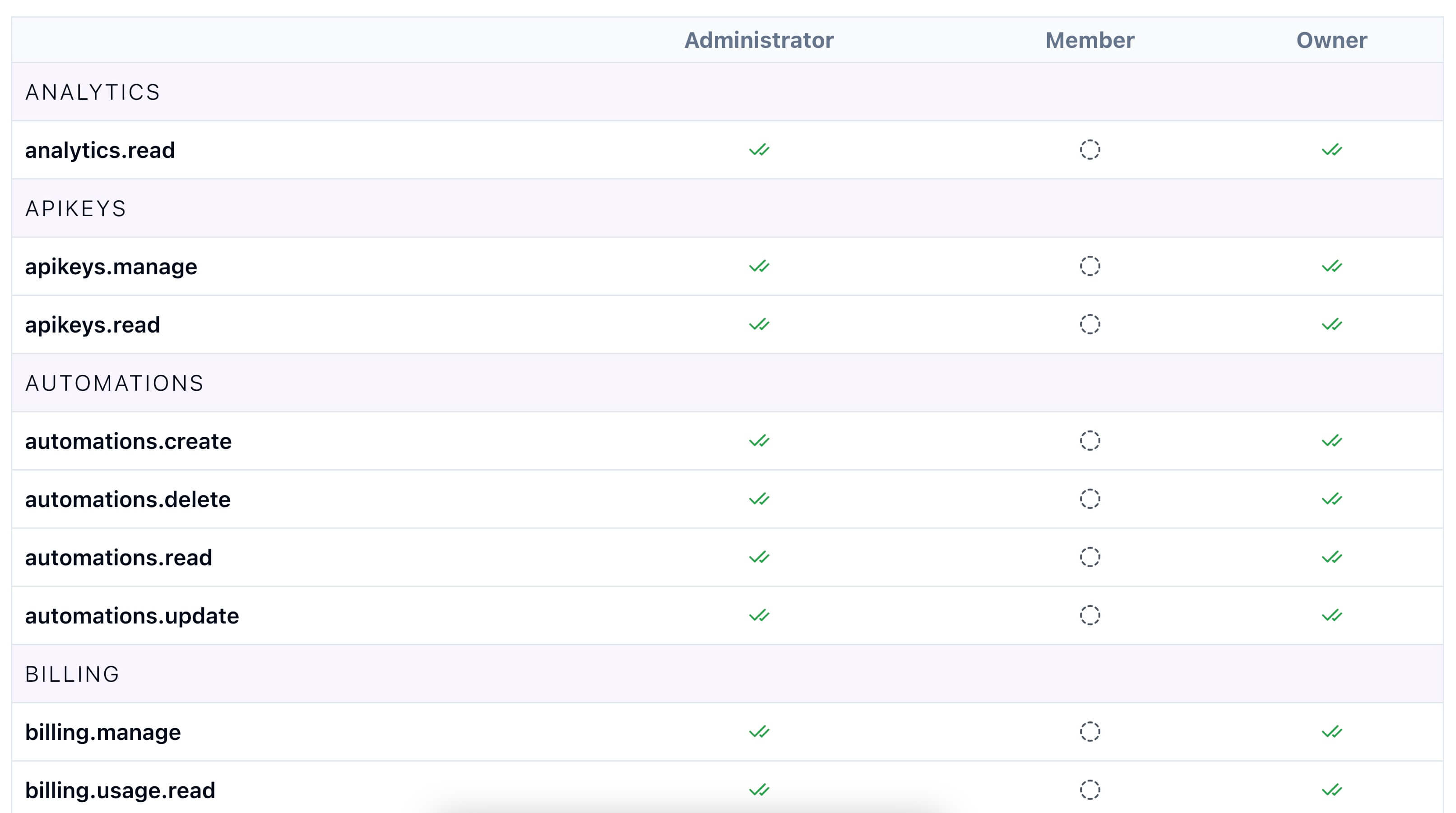
Manage access and permissions across your team with granular custom roles and permissions.
Stay up-to-date with the latest changes and improvements to Modelmetry.
Our pricing is simple and transparent.
For developers wanting to try out Modelmetry
For indie hackers and side projects
For startups and professionals
Have any questions? Use our live chat or email us at [email protected]
Modelmetry is an advanced platform designed to enhance the safety, quality, and appropriateness of data and models in applications utilizing Large Language Models (LLMs) like chatbots. It offers a comprehensive suite of evaluators to assess critical aspects such as emotion analysis, PII leak detection, text moderation, relevancy, and security threat detection.
With customizable guardrails, early termination options, and detailed metrics and scores, Modelmetry ensures that your LLM applications meet high standards of performance and safety. This robust framework provides actionable insights, safeguarding the integrity and effectiveness of your AI-driven solutions.
Modelmetry is ideal for developers and software engineers aiming to ensure their AI-driven applications are safe, reliable, and compliant with regulations.
Not at this stage. We prefer to focus on profitability so that we can provide a better service to our paying customers. We offer a very affordable Hobby plan at $9.99/month so that you can try our service without breaking the bank.
Modelmetry allows you to create and use custom evaluators tailored to your specific needs. This flexibility enables you to define criteria and metrics that are most relevant to your application, ensuring a more precise and effective evaluation process. You can also simply use an LLM-as-a-Judge evaluator with your own prompt.
Our client SDKs are open source. Our backend is proprietary because, well, it's our secret sauce. We can export all your data upon request.
We believe in keeping it simple for our customers and this means minimizing the hurdles to adoption. Our platform works out of the box; it's simple yet comprehensive. And if you want to leave, we can export all your data for you to download!
Modelmetry is committed to protecting your data privacy and security. We do not access payloads on your behalf, ever. We are a security-focused company and have implemented robust measures to ensure the confidentiality and integrity of your data. We use encryption, secure connections, and other industry-standard security practices to safeguard your data.
We do store inputs and outputs so you can review them alongside metrics and scores. We do not access payloads on your behalf, ever, unless you authorised us to do so.